Q: How long does it take VoiceBase to transcribe?
A: Moments.
Thanks to advances in technology such as deep learning, we find ourselves on the heels of an automated revolution: seemingly everything in our lives is becoming more automatic. According to Pew, 65 percent of Americans predict that “robots and computers will ‘definitely’ or ‘probably’ do much of the work currently done by humans” by 2065. VoiceBase is right at the forefront of this revolution with our trailblazing speech-to-text, allowing you to accurately and automatically transcribe conversations like never before.
Automatic Transcription is at the heart of richer voice insights and predictive analytics that will help you provide a more complete and powerful dataset to improve your business. So, how does it work? Take a look at the features that make our speech recognition solution the best in the industry.
FOR ENTERPRISE BUSINESS:
Request a Demo With Our Specialist Team
Our speech engines are finely tuned for processing large volumes of recorded calls or customer conversations from enterprise contact centers. Many of our customers are processing 1000,s+ inbound / outbound calls a day, and rely on our technology to accurately process, transcribe, and return data directly to their business intelligence dashboard within minutes.
Proof of Concept
If it makes sense to partner, we will assign our customer success team to your sample project. Our team works with you to deeply understand your business and how we can provide ROI. Often we request a sample data set from your call center, which we process and set up in your choice of visual analytics tool, such as Tableau.
Refinement
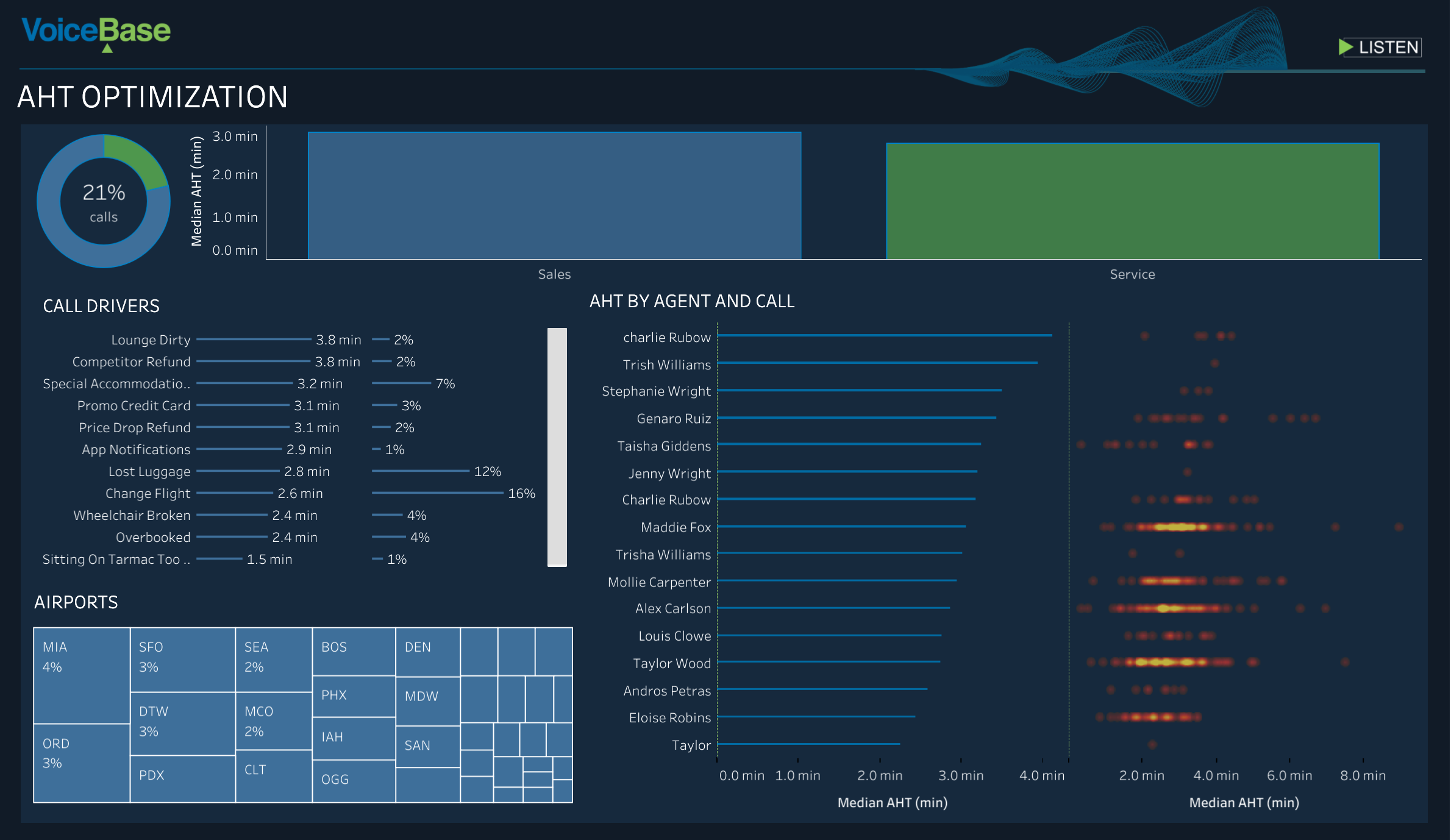
Once you are satisfied with our solution we will work on a joint proposal and plan for implementation. Depending on your use case our customer support team may be iterating with you throughout the instillation process. We work with you until you see proof of ROI. For example, imagine finding a trend or data point that allows you to reduce Average Handle Time (AHT) by 15%. If all the calls in your call center were 15% shorter, how much cost would your organization be saving?
FOR DEVELOPERS:
MACHINE GENERATED TRANSCRIPT
After you’ve been approved for an API Account through a consultation with a specialist, you have access to our Developer API. Once you upload a recording to the VoiceBase API, your audio will automatically be returned as a fully time-aligned, highly accurate transcript in a TXT, WORD, RTF, or SRT format. For Multichannel files, the JSON transcript would be returned.
PER WORD CONFIDENCE
Per Word Confidence is a measure of the acoustic similarity between the sound in the audio recording and the word that was transcribed. The Per Word Confidence score allows a user to locate certain keywords and grade them for accuracy from the transcription. This offers the opportunity to study content more granularly, which can provide a deeper understanding of valuable insights.
TIME-STAMPED WORDS
This feature allows users to surface specific words or phrases based on their time in a recording. Each time stamp is combined with a source URL and is applied to all of their stored recordings.
VoiceBase Player
Sometimes you get comfortable with tools you have already been using and are familiar with. VoiceBase’s Player allows you to continue using your player of choice but with the added benefits of our UI components. Enhanced features include an interactive transcript, automated keyword and topic extraction, user-defined keyword spotting, ad-hoc search, and transcript editor.
STEREO SPEAKER ID
It is now easier than ever to know who said what in a recording. With Stereo Speaker ID, you can automatically label the many speakers. There are several ways you can set up speaker identification, and other features such as keyword extraction and keyword spotting will include this feature.
SRT OUTPUT (CAPTIONING)
This tool can be used to create video captions from our automatic speech recognition technology within minutes. VoiceBase supports industry-standards closed-captioning formats (SRT and DFXP) that can be used with commercial video players and video delivery systems.
CUSTOM VOCABULARY
You can improve automatic transcription accuracy by inputting custom words into the Developer API. Some common examples include pronouns, company names, product names, and acronyms to help improve accuracy and keyword spotting.
Accurate automated transcription of recorded calls is just the beginning of what is possible with AI-Powered Voice Analytics.